大家好,我是毛毛。
今天是Day 18
終於要來看Deep Q-network~ ヽ(✿゚▽゚)ノ
這篇是2018年七月刊登在Trans. Emerg. Telecommun. Technol.上的論文。
Deep Q-network,和前面某一天提到的Deep Q-learning差別在於Deep Q-network有兩個神經網路。
以這篇論文來說,它用CNN作為它Deep Q-network中的神經網路,這兩個神經網路分別叫做:
evaluation network (eval-net)
target network (target-net)
整體的loss function是定義成Mean Square Error (MSE):
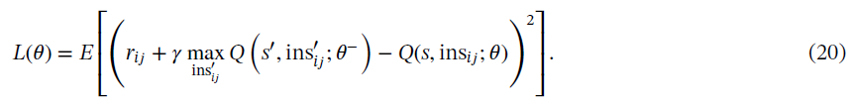
Gradient descent透過微分loss function得到:
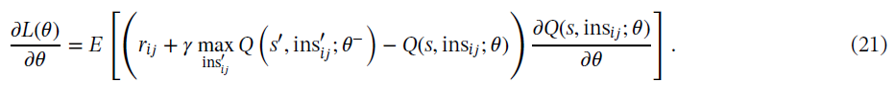
透過gradient descent和back propagation,可以得到最佳的Q-value
看完loss function和更新權重的部分後,現在來看Policy decision的部分
這邊就是在選擇action,而通常分為兩種方法:
Exploration
Exploitation
Exploration-Exploitation Dilemma
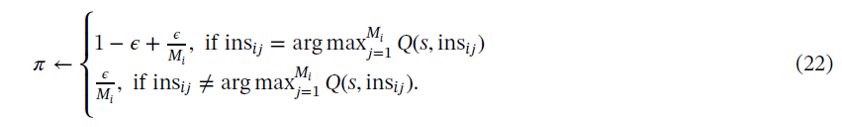
這邊還有另一個policy decision的問題
Multiarmed bandit problem這個問題是在說,現在有幾個單臂老虎機,組在一起就稱作Multiarmed bandit,問題就是,我們需要制定什麼樣的策略才能取得最大的獎勵,這裡假的每個老虎機的獎勵的隨機分布不同。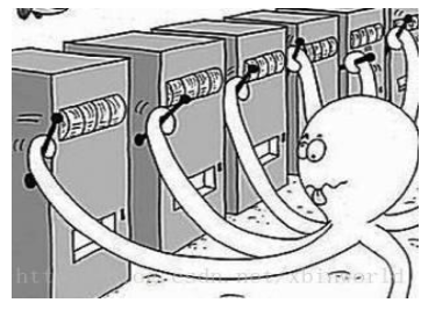
上圖來自PapersWithCode
解決MAB的演算法明天在講啦~
明天一早要報告,大家晚安 Zz(´-ω-`*)
明天見


 iThome鐵人賽
iThome鐵人賽